integer clamp
category: code [glöplog]
Quote:
=> Just let the compiler do it's job.
That was interesting. It might be fun to look at the assembly dump to see how much gets optimized out, though, before dismissing the branchless clamping completely =)
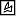
use unsigned comparison and CMOVcc

mmx indeed
Quote:
The PADDUS (Packed Add Unsigned with Saturation) instructions add the packed unsigned data elements of the source operand to the packed unsigned data elements of the destination operand and saturate the results.
PADDUS support packed byte (PADDUSB) and packed word (PADDUSW) data types.

Using no conditionals?
// if (number < 0) number = 0;
number &= ~number >>31;
// if (number > 0xFF) number = 0xFF;
number = number & 0xFF | ((-(((unsigned)number) >> 8)) >> 24);
Alternatively:
// if (number < 0) number = 0;
number &= ~number >>31;
// if (number > 0xFF) number = 0xFF;
number = 0xFF-number;
number &= ~number >>31;
number = 0xFF-number;
Whether this is faster than conditionals should depend on your platform. Platforms with built-in clamping, min/max or "set register if condition is true"-like instructions are unlikely to be faster with this code.
// if (number < 0) number = 0;
number &= ~number >>31;
// if (number > 0xFF) number = 0xFF;
number = number & 0xFF | ((-(((unsigned)number) >> 8)) >> 24);
Alternatively:
// if (number < 0) number = 0;
number &= ~number >>31;
// if (number > 0xFF) number = 0xFF;
number = 0xFF-number;
number &= ~number >>31;
number = 0xFF-number;
Whether this is faster than conditionals should depend on your platform. Platforms with built-in clamping, min/max or "set register if condition is true"-like instructions are unlikely to be faster with this code.
las: Now try benchmarking again with something that isn't trivially branch-predictable by the CPU. :-)
Sesse: Does it really matter? The compiler probably turned those branches into CMOVs anyway...

yeh.... does it really matter? :) seems a theme on pouet these days.. in this day and age of optimised compilers why are people still discussing this? I'm sure there are many other flaws in your code that impact perf more :)
Sesse:
Benchmark it yourself ;)
Quote:
// Just some not so serious testing...
Benchmark it yourself ;)

Of course the real power of nonconditional version is that you can do simd without simd..
sum0 = a0+b0 | (a0+b0>>8&0x801008)*255;
sum1 = a1+b1 | (a1+b1>>8&0x801008)*255;
*dest = sum0<<1&0xf81f0000 | sum0<<16&0x7e00000 | sum1>>15&0xf81f | sum1&0x3e0;
sum0 = a0+b0 | (a0+b0>>8&0x801008)*255;
sum1 = a1+b1 | (a1+b1>>8&0x801008)*255;
*dest = sum0<<1&0xf81f0000 | sum0<<16&0x7e00000 | sum1>>15&0xf81f | sum1&0x3e0;
